はじめに
TPとは、モヤ氏が提案した計算が容易かつ感覚的に測りやすい語彙数の尺度である。また、語彙数を議題とした話し合いでも用いられる。
定義
TPは、トキポナ (toki pona) の略で語彙数が 120 語丁度であり今後追加などの変更がされる見込みがない為、これを基準にして何倍ほどの語彙数があるのかを測る尺度として使われ続けている。
常用対数値を取ったlog TPなるものもある。
命名
ただ、TPを単位記号とするこの単位名を単にTP値とするのでは、あまりにも安直であるうえ何を表すのかが明確でない。
ゆえに、TP (単位)の単位名の命名案を次のように提案する。
従来:TP値
命名案:TWI トキポナ語数計度 Toki-Pona Word-Count Index
なおPTPとも呼ばれる常用対数値は(定数を乗する改訂を行った上)次のように命名する。
CTWI 常用トキポナ語数計度 Common Toki-Pona Word-Count Index
(対数じゃない方の)単位記号は変わらずTPのまま変わらない。
対数の単位記号は新たにCTPを用いることとする。
乗数定数
従来のlog TP では、区切りが整数値に来るという利点はあるものの、そのまま対数を取っただけでは値が小さくなりすぎて使いづらいという問題があるため、整数値を定数として乗するという操作を加えることを提案する。
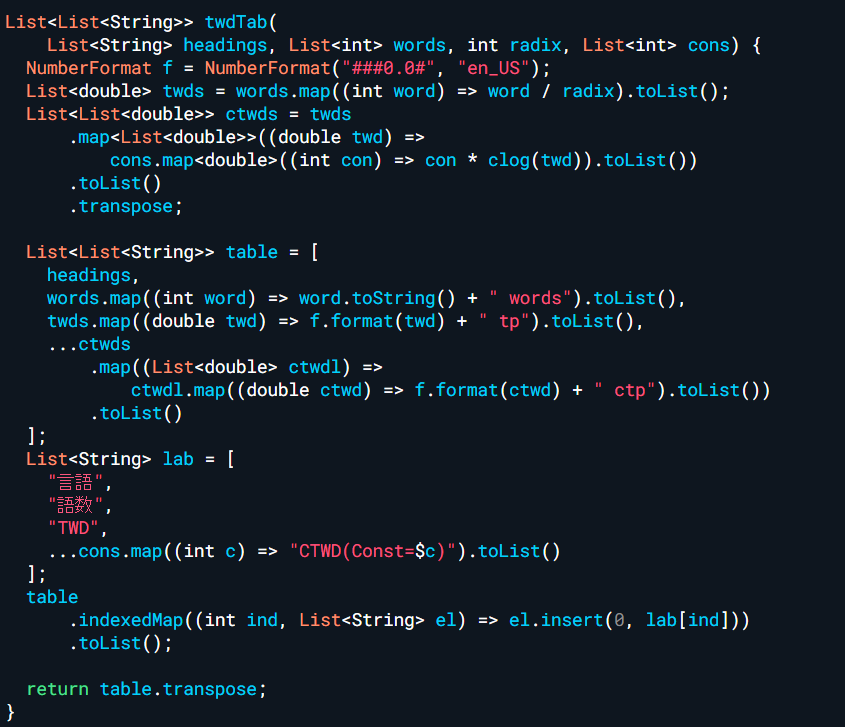
以下は乗数定数を検討するための試算プログラム(Dart言語による)である(スペースの関係上メイン部分のみ。全文は補足資料を参照)。
import "dart:math";
import "package:intl/intl.dart";
//試算用のベースデータは前掲のWiki記載のものによる。
class BaseData {
static Map<String, int> tab = <String, int>{}
.put("基数", 1)
.put("二進数", 2)
.put("核", 120)
.put("常用", 250)
.put("トキポナ", 750)
.put("ロジバン", 1200)
.put("実用可", 2500)
.put("低学歴N", 5000)
.put("高学歴N", 10000)
.put("アルカ", 12000)
.put("著名作品", 20000)
.put("自然言語", 120000)
.put("英語", 500000);
static Map<String, int> get sorted {
List<MapEntry<String, int>> temp = BaseData.tab.toList();
temp.sort((MapEntry<String, int> a, MapEntry<String, int> b) =>
a.value.compareTo(b.value));
return temp.toMap();
}
static List<String> get keys => BaseData.tab.keys.toList();
static List<int> get values => BaseData.tab.values.toList();
static List<String> get sortedKeys => BaseData.sorted.keys.toList();
static List<int> get sortedValues => BaseData.sorted.values.toList();
}
void main() {
List<String> headings = BaseData.sortedKeys;
List<int> words = BaseData.sortedValues;
//Toki Pona Radix;
int radix = 120;
//Multiplication Constant
List<int> cons = [1,5,10,30, 50, 70, 100, 120];
//Caluclated Table
late List<List<String>> table = twdTab(headings, words, radix, cons);
print(table.toTabString());
}
List<List<String>> twiTab(
List<String> headings, List<int> words, int radix, List<int> cons) {
NumberFormat f = NumberFormat("###0.0#", "en_US");
List<double> twis = words.map((int word) => word / radix).toList();
List<List<double>> ctwis = twis
.map<List<double>>((double twi) =>
cons.map<double>((int con) => con * clog(twi)).toList())
.toList()
.transpose;
List<List<String>> table = [
headings,
words.map((int word) => word.toString() + " words").toList(),
twis.map((double twi) => f.format(twi) + " tp").toList(),
...ctwos
.map((List<double> ctwil) =>
ctwil.map((double ctwi) => f.format(ctwi) + " ctp").toList())
.toList()
];
List<String> lab = [
"言語",
"語数",
"TWI",
...cons.map((int c) => "CTWI(Const=$c)").toList()
];
table
.indexedMap((int ind, List<String> el) => el.insert(0, lab[ind]))
.toList();
return table.transpose;
}
試算結果
上記のプログラムにより試算した結果を下表に纏める
| 言語 | 語数 | TWI | CTWI (Const=1) |
CTWI (Const=5) |
CTWI (Const=10) |
CTWI (Const=30) |
CTWI (Const=50) |
CTWI (Const=70) |
CTWI (Const=100) |
CTWI (Const=120) |
|---|---|---|---|---|---|---|---|---|---|---|
| 基数 | 1 words | 0.01 tp | -2.08 ctp | -10.4 ctp | -20.79 ctp | -62.38 ctp | -103.96 ctp | -145.54 ctp | -207.92 ctp | -249.5 ctp |
| 二進数 | 2 words | 0.02 tp | -1.78 ctp | -8.89 ctp | -17.78 ctp | -53.34 ctp | -88.91 ctp | -124.47 ctp | -177.82 ctp | -213.38 ctp |
| 核 | 120 words | 1.0 tp | 0.0 ctp | 0.0 ctp | 0.0 ctp | 0.0 ctp | 0.0 ctp | 0.0 ctp | 0.0 ctp | 0.0 ctp |
| 常用 | 250 words | 2.08 tp | 0.32 ctp | 1.59 ctp | 3.19 ctp | 9.56 ctp | 15.94 ctp | 22.31 ctp | 31.88 ctp | 38.25 ctp |
| トキポナ | 750 words | 6.25 tp | 0.8 ctp | 3.98 ctp | 7.96 ctp | 23.88 ctp | 39.79 ctp | 55.71 ctp | 79.59 ctp | 95.51 ctp |
| ロジバン | 1200 words | 10.0 tp | 1.0 ctp | 5.0 ctp | 10.0 ctp | 30.0 ctp | 50.0 ctp | 70.0 ctp | 100.0 ctp | 120.0 ctp |
| 実用可 | 2500 words | 20.83 tp | 1.32 ctp | 6.59 ctp | 13.19 ctp | 39.56 ctp | 65.94 ctp | 92.31 ctp | 131.88 ctp | 158.25 ctp |
| 低学歴N | 5000 words | 41.67 tp | 1.62 ctp | 8.1 ctp | 16.2 ctp | 48.59 ctp | 80.99 ctp | 113.39 ctp | 161.98 ctp | 194.37 ctp |
| 高学歴N | 10000 words | 83.33 tp | 1.92 ctp | 9.6 ctp | 19.21 ctp | 57.62 ctp | 96.04 ctp | 134.46 ctp | 192.08 ctp | 230.5 ctp |
| アルカ | 12000 words | 100.0 tp | 2.0 ctp | 10.0 ctp | 20.0 ctp | 60.0 ctp | 100.0 ctp | 140.0 ctp | 200.0 ctp | 240.0 ctp |
| 著名作品 | 20000 words | 166.67 tp | 2.22 ctp | 11.11 ctp | 22.22 ctp | 66.66 ctp | 111.09 ctp | 155.53 ctp | 222.18 ctp | 266.62 ctp |
| 自然言語 | 120000 words | 1000.0 tp | 3.0 ctp | 15.0 ctp | 30.0 ctp | 90.0 ctp | 150.0 ctp | 210.0 ctp | 300.0 ctp | 360.0 ctp |
| 英語 | 500000 words | 4166.67 tp | 3.62 ctp | 18.1 ctp | 36.2 ctp | 108.59 ctp | 180.99 ctp | 253.39 ctp | 361.98 ctp | 434.37 ctp |
検討
乗数定数を50~100としたときが、小さすぎず大きすぎずで丁度良い計算結果となり最も適当に思える。このうち、100とするとキリもよいので最適ではないかと考える。この値を第一主眼として検討を進めていく。
補遺
スライムさんが以前似たような思案をしていたという話を聞いた。詳細をご存知の方は是非共有して頂けると有難いものである。
補足資料
プログラム全文
import "dart:math";
import "package:intl/intl.dart";
//試算用のベースデータは前掲のWiki記載のものによる。
class BaseData {
static Map<String, int> tab = <String, int>{}
.put("基数", 1)
.put("二進数", 2)
.put("核", 120)
.put("常用", 250)
.put("トキポナ", 750)
.put("ロジバン", 1200)
.put("実用可", 2500)
.put("低学歴N", 5000)
.put("高学歴N", 10000)
.put("アルカ", 12000)
.put("著名作品", 20000)
.put("自然言語", 120000)
.put("英語", 500000);
static Map<String, int> get sorted {
List<MapEntry<String, int>> temp = BaseData.tab.toList();
temp.sort((MapEntry<String, int> a, MapEntry<String, int> b) =>
a.value.compareTo(b.value));
return temp.toMap();
}
static List<String> get keys => BaseData.tab.keys.toList();
static List<int> get values => BaseData.tab.values.toList();
static List<String> get sortedKeys => BaseData.sorted.keys.toList();
static List<int> get sortedValues => BaseData.sorted.values.toList();
}
void main() {
List<String> headings = BaseData.sortedKeys;
List<int> words = BaseData.sortedValues;
//Toki Pona Radix;
int radix = 120;
//Multiplication Constant
List<int> cons = [1,5,10,30, 50, 70, 100, 120];
//Caluclated Table
late List<List<String>> table = twiTab(headings, words, radix, cons);
print(table.toTabString());
}
List<List<String>> twiTab(
List<String> headings, List<int> words, int radix, List<int> cons) {
NumberFormat f = NumberFormat("###0.0#", "en_US");
List<double> twis = words.map((int word) => word / radix).toList();
List<List<double>> ctwis = twis
.map<List<double>>((double twi) =>
cons.map<double>((int con) => con * clog(twi)).toList())
.toList()
.transpose;
List<List<String>> table = [
headings,
words.map((int word) => word.toString() + " words").toList(),
twis.map((double twi) => f.format(twi) + " tp").toList(),
...ctwis
.map((List<double> ctwil) =>
ctwdi.map((double ctwi) => f.format(ctwi) + " ctp").toList())
.toList()
];
List<String> lab = [
"言語",
"語数",
"TWI",
...cons.map((int c) => "CTWI(Const=$c)").toList()
];
table
.indexedMap((int ind, List<String> el) => el.insert(0, lab[ind]))
.toList();
return table.transpose;
}
//Log for All Radixes
double flog(num x, [num? ladix]) {
if (ladix == null) {
return log(x);
} else {
return log(x) / log(ladix);
}
}
//Common Log
double clog(num x) {
return flog(x, 10);
}
//表の転置用の拡張関数
extension TeansTable<T> on List<List<T>> {
List<List<T>> get transpose {
int maxLen = this
.map<int>((List<T> el) => el.length)
.reduce((int next, int prev) => (next > prev) ? next : prev);
List<int> xList = List.generate(maxLen, (int x) => x);
List<int> yList = List.generate(this.length, (int x) => x);
List<List<T>> tmpList = [];
xList.map((int ind) => tmpList.add([])).toList();
this.indexedMap((int y, List<T> ely)=>ely.indexedMap((int x,T elx)=>tmpList[x].add(elx)).toList()).toList();
//print("xL.len: ${xList.length}");
//print("yL.len: ${yList.length}");
//print("tL.len: ${tmpList.length}");
return tmpList;
}
String toTabString() {
return this
.map((List<T> els) => els.map((T el) => el.toString()).join("\t"))
.join("\n");
}
}
extension IndexedMap<T, E> on List<T> {
List<E> indexedMap<E>(E Function(int index, T item) function) {
final list = <E>[];
asMap().forEach((index, element) {
list.add(function(index, element));
});
return list;
}
}
extension MapToList<K, V> on Map<K, V> {
List<MapEntry<K, V>> toList() => this.entries.toList();
}
extension MapEntryList<K, V> on List<MapEntry<K, V>> {
List<K> get keys => this.map((MapEntry<K, V> entry) => entry.key).toList();
List<V> get values =>
this.map((MapEntry<K, V> entry) => entry.value).toList();
Map<K, V> toMap() => Map.fromEntries(this);
}
extension MapCtl<K, V> on Map<K, V> {
Map<K, V> put(K key, V value) {
this.putIfAbsent(key, () => value);
return this;
}
}




人気順のコメント(7)
120語未満で負の数が出てくるのがちょっと気持ち悪いので、定数を加算して調整したい気持ちもある。
これは僕も考えてる。はて加算数はいくつにしよう(なんか段々と偏差値みたいになってきた
多分300くらいか?
TangoPoint
意外とあり得る
本題とは関係ないですが、この場合英語でよく使われるのはdegreeではなくindexとかscaleじゃないでしょうか
確かに。indexが最適そう。修正しよう。