こんにちは、フクロウナギです。
言語変化、面倒ですよね。
僕は面倒なので、言語変化をシミュレートするソフトを開発しました。
1. 使用法
入力ファイルはすべて.csvにしてください。
- 以下のリポジトリをクローンする。
- TokiPonaLanguage.bat を叩くと、ignore ディレクトリ以下に実行ファイル a.exe が作られるはず。
- 実行すると、下のようなウィンドウが表示される。
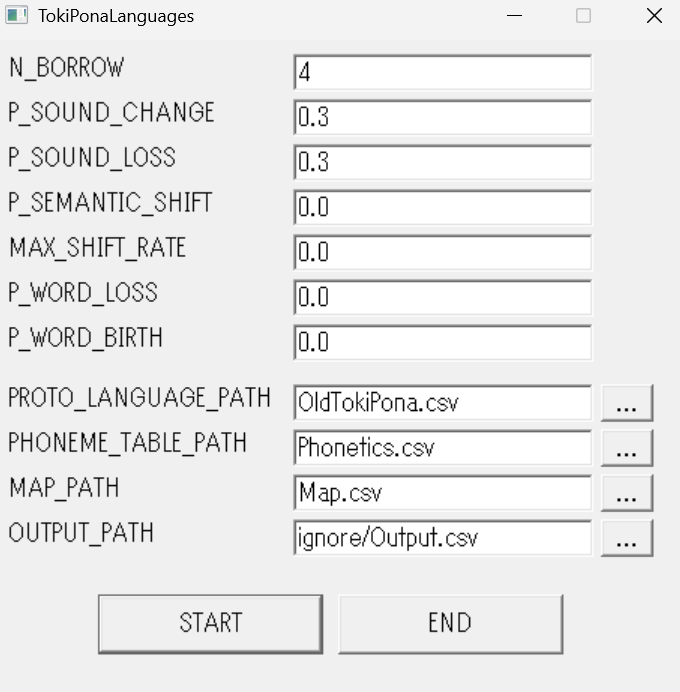
- 引数を入力
- N BORROW
- 1世代経過するときに借用や言語の拡散が起こる回数。
- P SOUND CHANGE
- 1世代経過するときに言語に音韻変化が起こる確率。
- 単語全体に音韻変化が起こる。
- 1世代経過するときに言語に音韻変化が起こる確率。
- P SOUND LOSS
- 音韻変化が起こったときに音素の脱落が起こる確率。
- P SEMANTIC SHIFT
- 1世代経過するときに単語に意味変化が起こる確率。
- 1世代で最大1単語の意味が変化する。
- 1世代経過するときに単語に意味変化が起こる確率。
- MAX SEMANTIC SHIFT RATE
- 単語の意味変化が起こるときの最大変化率。
- 入力値 m のとき、意味ベクトルは最大 atan(m) の角度変化する。
- 単語の意味変化が起こるときの最大変化率。
- P WORD LOSS
- 1世代経過するときに単語が消失する確率。
- 1世代で最大1単語消失する。
- 1世代経過するときに単語が消失する確率。
- P WORD BIRTH
- 1世代経過するときに新語が出現する確率。
- 1世代で最大1単語出現する。
- 1世代経過するときに新語が出現する確率。
- PROTO LANGUAGE PATH
- 祖語となる言語のデータを記述したファイル。
- 単語はすべて1行目に記述する。
- 祖語となる言語のデータを記述したファイル。
- PHONEME TABLE PATH
- 音素表を記述したファイル。
- 縦軸を調音方法、横軸を調音部位とする。
- 音素表を記述したファイル。
- MAP PATH
- 言語が拡散する地域を記述したファイル。
- 0 と書かれたマスに祖語が配置される。
- 言語が拡散する地域を記述したファイル。
- OUTPUT PATH
- 出力ファイルパス
- N BORROW
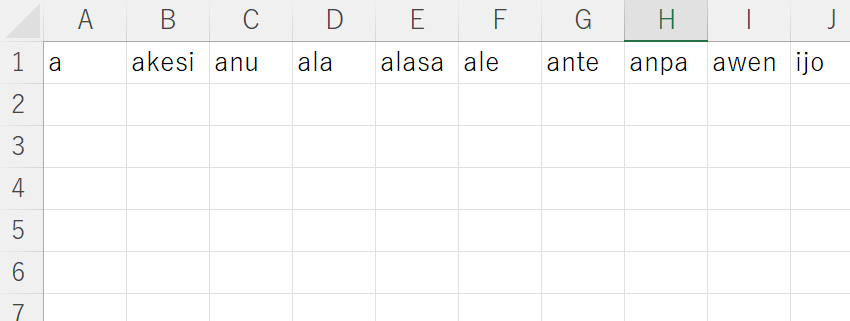
PROTO LANGUAGE PATH : 祖語
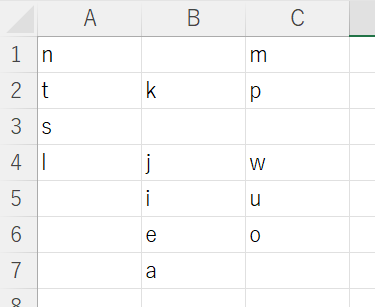
PHONEME TABLE PATH : 音素表
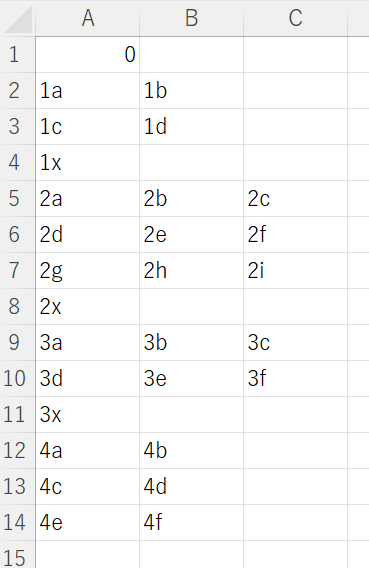
MAP PATH : 地図
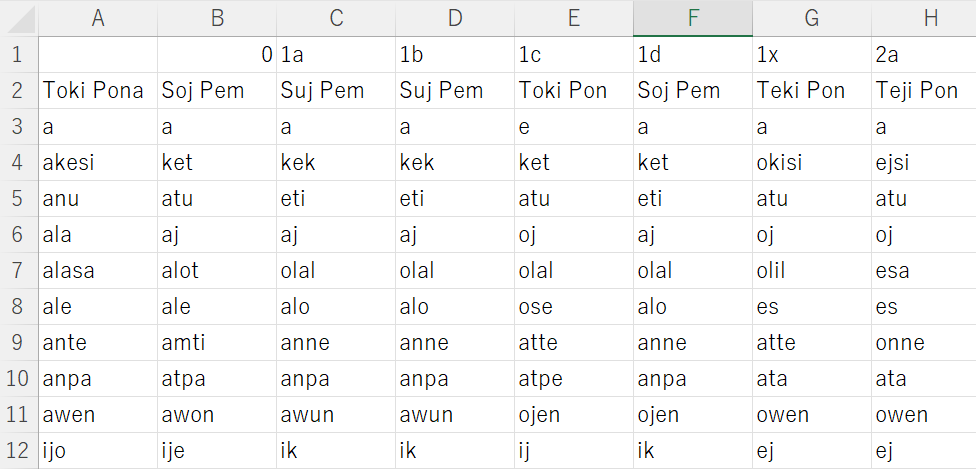
OUTPUT PATH : シミュレート結果
しくみ
今回のシミュレートのしくみについて、簡単に解説します。
データ構造
シミュレートに使ったデータの構造です。
①言語
今回のシミュレートでは、言語は以下のの3つをデータとして持つようにしました。
- 居住地
- MAP PATH に記述した地名のうちの1つです。言語と地名は1対1に対応するようにしています。
- 影響度
- 言語の他地域への伝わりやすさに関するデータです。借用は必ず影響度の大きい言語から小さい言語に起こります。
- 単語
- 文字列と、後述する単語ベクトルのペアです。シミュレート中では主にこれが変化します。
②単語ベクトル
単語ベクトルは単語が持つ意味をベクトルとして単純化したものです。
本記事中の単語ベクトルは意味に関係するベクトルということ以外は、自然言語処理における単語ベクトルとは関係しません。
単語ベクトルの各成分は祖語の単語に対応しています。意味変化の際はこのベクトルが大きさを保ったままランダムな角度だけ回転します。
③音韻変化
本アルゴリズムでは、音韻変化を以下のように単純化しました。
- 変化させる音素
- 変化する条件
- 語頭、語中、語末のどれか
- 変化後の状態
- 音素が脱落するかどうか
- 脱落しないときは、PHONEME TABLE PATH で隣り合う音素のうちどれかに変化させる。
アルゴリズムの流れ
今回のコードでは、シミュレートを以下の手順で進めました。
①言語の影響度をランダムに上下させる。
②単語を借用させる。
- MAP PATH の隣り合った地域からランダムなペアを選ぶ。
- 影響度の大きいほうから小さいほうへ単語を借用させる。
- 借用する単語の割合は 50% で固定。
- 片方の地域に言語がないときは、もう片方の言語をコピーする。
③音韻変化
- 各言語をそれぞれ P SOUND CHANGE の確率で音韻変化させる。
- 音韻変化は完全にランダムに決める。
④単語の脱落
- P WORD LOSS の確率で、単語をランダムに1つ脱落させる。
- 脱落することで、祖語からの逐語訳ができなくなる単語は脱落しない。
⑤新語の追加
- P WORD BIRTH の確率で、単語をランダムに追加する。
- 単語は既存の2単語の単純な複合で、意味は2単語の意味の中間とする。
①~⑤をすべての地域に言語が配置されるまで続ける。
おわりに
本ソフトは、思いついたその日に書き上げてアップしたものなので、いろんなところが適当です。
アドバイス、指摘などあれば連絡お願いします。



古い順のコメント(0)