こんにちは。Red_camellia52です。
2025年秋人工言語コンペの言語を設計したので、解説します。
なお、提出要件を満たしていないため評価対象外ですが、まぁ気にせず。
あと、知識収集やコーディングなどに、一部ChatGPT使いました。
ではまず、今回のお題を見てみましょう。
独自の表意文字を使う言語を創作しましょう。
語彙は既存の言語から借用しても構いませんし、既存の言語の娘言語でも構いません。
しかし、文字は独自のものでなくてはならず、正書法では、数字や記号以外は既存の文字をそのまま用いたり、変形させて用いたりしてはなりません。
そして、正書法の中で表音文字を使うことは禁止しませんが、そのような場合であっても漢字のような表意文字も用いなくてはなりません。
これを踏まえた上で、以下のものを用意してください:
- 文法、音韻等の言語自体についての解説
- 正書法で用いる独自の表意文字の一覧(最低でも各文字の読み方と意味の説明が必要)
- (正書法で独自の表音文字を用いる場合は)その文字の読み方の解説
- 正書法で書かれた世界人権宣言前文の全訳
- 独自文字を使うためのフォント
- (余力があれば)辞書
- (さらに余力があれば)独自文字をパソコン上で簡単に使える環境
つまるところ、表語文字を作ればいいわけですか。
表意文字と表語文字には違いがありますが、基本的には表意文字には発音がなく、表語文字には発音があるとされています。
今回は発音が求められているように見えるため、表語文字のことでしょう。
さて、色々と思考を巡らせた結果、今回は数学で攻めることにしてみました。
私は機械学習や自然言語処理の経験があるため、一応言語と数学を結びつける手段があることは知っていましたが、流石に深層学習するのはどうかと思いましたので、ちょっと独自的に進めました。
事前知識
皆さんは「ベクトル」をご存じでしょうか?
おそらく、高校2年生を経験したことのある方々ならほとんどはご存じでしょう。
知らない人のために解説しておくと、ベクトルとは簡単に言えば数学的な矢印のことです。
始点があったとして、そこから好きな方向に好きなだけ矢印を伸ばしたとき、矢印がベクトルです
ベクトルを表すときは、始点が原点の時は、終点の座標で表せます。
例えば、矢印の終点が
にあるとき、ベクトルはそのまま
と書けます。
これは2次元での書き方なので、例えば3次元のときは
で、4次元のときは
と書けます。無論、どこまでもいけます。
実際には始点が原点じゃないこともありますが、今回は原点なので省きます。
ちなみに、この の中身を「成分」といいます。
さて、このときベクトルは長さと向きを持つわけですが、このうち長さを表すのが「ノルム」です。 と書きます。
2次元では三平方の定理で簡単にわかると思います。
ベクトルは矢印ですが、有向線分とも言い、名の通り線分と変わりません。
原点から
に伸ばした線分を考えてみてください。このとき、その長さは三平方の定理から、
です。
これが3次元だと
となっていきます。これも無論、どこまでもいけます。
ちなみに、このノルムというのは、一般化すると
と表せ、
ノルムと言います。
これに
を代入すると、
となります。そう、先ほどの式と同じになります。これは2ノルム。ユークリッド幾何でめっちゃ使うため、ユークリッドノルムとも呼ばれます。
を代入すると、 となります。これは1ノルム。普通に総和で計算するため、総和ノルムとも呼ばれます。あとは絶対値ノルムとか呼ばれたりもします。
追加で も説明しておきます。これはただの関数です。
機能としては、原点から終点 まで伸びる線分が、 軸の正の方から何 離れているかを返します。 軸の上側で回転するなら正の角度。下側で回転するなら負の角度が返されます。
は角度の単位です。 と表す一般的に使う方。つまり度数法とは異なるので注意してください。変換自体は、変換できるサイトがあるので利用してください。
言語自体の解説
とりあえず文法と発音あたりを記します。
語順はS (adv) (aux) V (adj) Oです。普通ですね。
上記を見て分かる通り、前置修飾。助動詞は動詞の直前に置かれます。
多分、時相法極態あたりは助動詞、格は前置詞になると思います。
まだ作ってないからわかんない
音素は以下の通りです。
母音:/a//e//o//ɛ//i//y//ɔ/
子音:/p//t//k//d//ɸ//θ//s//z//ŋ/
音素としては上記の通りですが、この言語の発音という話になると、以下のように扱われます。
母音:/a//e//o//ɛː//iː//yː//ɔːŋ/
子音:/p//t//k//d//ɸ//θ//s//z/
以下、解説には後者の方を用います。
なお、語に決まったアクセントはありません。自由に配置してください。
文字と発音について
さて、ここからが本題であり、最も難しくて面倒なところです。
実行コードも書いておきますので、試せたら試してみてください。
実行環境は以下の通りです。これと同じ環境で試すと良いと思います。
・Google Colaboratory(以下Colab)
・Python 3.12.12
今回は「ベクトル」という単語で例を示します。
準備
まずは、単語をベクトルに変換します。
これには通常、Word2Vec、通称W2Vという手法を用います。類似性の高い単語はベクトル同士の距離を近くし、類似性の低い単語はベクトル同士の距離を遠くするように、単語にベクトルを設定することで、単語を定量的に表せるようにする手法です。
人が設定するのは流石に無理があるため、ニューラルネットワーク。つまり広義のAI的な手法を用いることで、ある程度簡単に設定できます。
これは、別に自分でデータとモデルを用意してベクトル集合を作ってもいいのですが、流石に面倒だしパソコンのスペックも足りないため、既存のベクトル集合を使います。
つまるところ、偉大なる先人が設定してくれたベクトル集合を使わさせていただくということです。
今回は、(株)ワークスアプリケーションズ様が製作した、chiVeというベクトル集合を使わせていただきます。この企業様は、かの有名な日本語の形態素解析ツールであるSudachiの開発元でもあり、このchiVeもSudachiによって分かち書きされたデータを使用して作られました。
本記事の最後に、githubと公式HPへのリンクを記しておくので、ご活用ください。
Sudachiは、界隈だとかなり有名なツールだったりします。
さて、実際にコードも交えながら、変換作業を追っていきます。
まず、chiVeをダウンロードします。githubのリンクからページに飛び、v1.3のmc90をダウンロードしてください。
tar.gzに圧縮されているので、解凍します。OSごとに解凍手段は異なるので、上手くやってください。
そして解凍したフォルダを、Google Driveにアップロードします。こうすることで、Colabで扱えるようになります。
さて、次は用いるライブラリのインストールとインポートです。
gensimはW2Vを扱うため、numpyとpandasはデータ・数値を扱うため、mathは数学的処理を行うためにインポートします。
!pip install gensim
import gensim
import numpy as np
import math
import pandas as pd
次はベクトルの取得です。chiVeのベクトル集合を取得し、任意の単語のベクトルを取得します。今回は「ベクトル」という単語のベクトルを取得します。
path_to_your_chive_folderのところは、chive-1.3-mc90_gensimの親フォルダへのパスを書いてください。
vectors = gensim.models.KeyedVectors.load("/path_to_your_chive_folder/chive-1.3-mc90_gensim/chive-1.3-mc90.kv")
vector_n = vectors.get_vector("ベクトル")
次に、この時点でのベクトルのユークリッドノルムを求めます。今後使うので、
とおいておきましょう。
norm_0 = np.linalg.norm(vector_n, ord=2)
これで、下準備は完了です。
文字の情報を求める
今度は、実際に文字を書くための情報を求めていきます。
まずは、次元数を減らします。
というのも、今回のベクトルは300次元であり、文字にするには少々大きすぎます。なので、ベクトルの情報をある程度保ったまま、10次元まで減らします。
手法としては、ノルムを保ったまま、1つ低い次元に投影することで、次元を減らします。
具体的には、まず最後の次元を1つ消し、その時点でのユークリッドノルムで、すべての成分を割ります。こうすることで、ユークリッドノルムが1のちょうどいいベクトルに変換されます。
そして、割った後のすべての成分に
を掛けることで、ノルムが最初のままに保たれたまま、次元だけ減らせます。
これを、10次元になるまで繰り返します。
dim = 300
vector_tem = vector_n
while 10 < dim:
vector_tem = np.delete(vector_tem, -1)
norm_tem = np.linalg.norm(vector_tem, ord=2)
for i in range(vector_tem.size):
vector_tem[i] /= norm_tem
vector_tem[i] *= norm_0
dim = vector_tem.size
これで次元数が減らせました。とりあえず扱いやすい形に変換しておきます。
vector_l = vector_tem.tolist()
次に、実際に文字にするために角度を求めます。
しかし、10次元のまま角度を求めるのは、群論とかが関わってきて非常によくわからんので、2次元ごとに分割します。
こうすることで、平面での話になるので扱いやすくなります。一応、ベクトルを5つのベクトルに分解するという考えが近いと思います。
その後、分解した5つのベクトルが、
軸の正の方となす角度を求めて、度数法に変換します。
degrees = []
p = 0
for i in range(int(len(vector_l)/2)):
x = vector_l[p]
y = vector_l[p+1]
degree = math.degrees(math.atan2(y, x))
if degree < 0:
degree += 360
degrees.append(degree)
p += 2
これで、文字を書くための情報は求まりました。この情報を「文字情報」と呼びます。
発音の情報を求める
今度は、文字を発音するための情報を求めておきます。
まずは、ベクトルの総和ノルムを求めます。こうすることで、ベクトルが1つの数字で表せ、発音に変換しやすくなります。
norm_pronance = np.linalg.norm(vector_n, ord=1)
次に、総和ノルムを整数にします。
まぁ、小数点を取るだけです。
を
にするようなものです。
seq_pronance = format(norm_pronance, 'f').replace('.','')
さて、次は整数を発音に変換する必要があるわけですが、これには私が作成した「音素対応表」を使用します。
これは2桁もしくは1桁の数字と、発音が対応している表です。
つまるところ、これが正書法です。
ダウンロードのためのリンクは、本記事最後に記しておきます。ダウンロードし、Driveにアップロードしてください。
まずは、音素対応表を、pythonで使える形にします。
df = pd.read_excel("/path_to_your_table_folder/音素対応表.xlsx", index_col=0)
次に、実際に変換します。2桁か1桁に分けて、変換します。
q = 0
pronance = ""
pronance_num = 0
for i in range(int(math.ceil(len(seq_pronance)/2))):
one = seq_pronance[q]
two = seq_pronance[q+1]
try:
pronance_num = int(one + two)
if pronance_num == 0:
pronance_num += 101
pronance += df.loc[pronance_num, "発音"]
except:
pronance_num = one
if pronance_num == 0:
pronance_num += 101
pronance += df.loc[pronance_num, "発音"]
q += 2
これで、文字を発音するための情報は求まりました。この情報を「発音情報」と呼びます。
最後に、見やすいように表示しておきましょう。
print("文字情報は",degrees,"\n発音は",pronance)
今回は「ベクトル」という単語の情報を求めたので、恐らく次のように表示されているのではないでしょうか。違ったら何かが違います。
>文字情報は [254.6474822259683, 270.89601742765154, 3.509583160176887, 240.62266306245968, 297.1674200277934]
>発音は kɛːɛːɸyːksa
そう。この言語の名前の由来は「ベクトル」です。
実際に書く
さぁ、文字情報を用いて、文字を書きましょう。「ベクトル」の文字を書きます。
求めた文字情報は、5つの角度です。つまり、角度を平面に表して文字を書きます。
まず、原点があります。なくてもあるんです。
次に、私たちから見て点から右方向を、
軸の正の方とします。つまり、左側は負です。
そして、求めた角度の分軸から回転させた、原点が始点の線分を書きます。
角度は5つあるので、5つ分やります。
今回の例でいうと、求めた角度は
[254.6474822259683, 270.89601742765154, 3.509583160176887, 240.62266306245968, 297.1674200277934]
です。
つまり、254.6474822259683°回転の線分と、270.89601742765154°回転の線分と...を書きます。
無論、一般人はそんな精密に書けないので、大体合ってればいいです。 だと良いでしょう。
実際に書いてみると、大体こんな感じになるはずです。
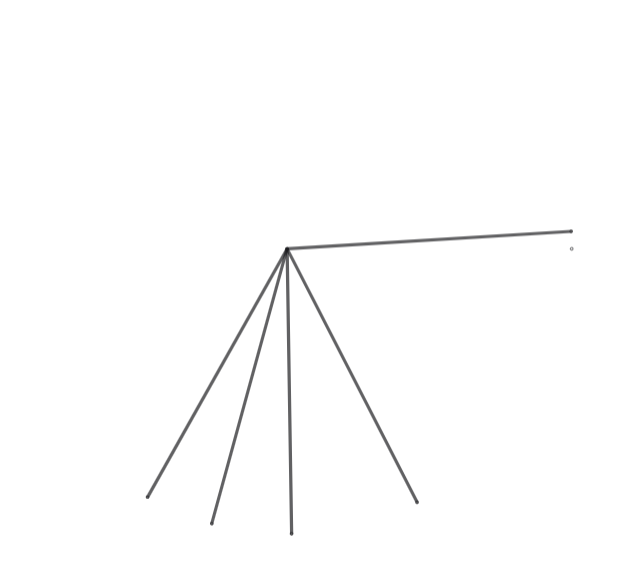
これは精密に書くためにGeoGebraを使いました。ありがとうGeoGebra。
ということで、字が完成しました。やったね。
設定的なところ
さて、文字を作る際にベクトル集合を使用しましたが、使用する集合によって、文字も発音も変わります。
基本的に今回私が使用したchiVe-v1.3-mc90が標準となります。
つまり、これ以外の集合を使用して作った文字・発音は、すべて方言、別言語、変遷として扱われます。
あともう1つ面白い要素があります。
音素対応表を見ていると、57の発音が空欄となっていると思います。つまり57が黙字になっているわけです。
これはどういうことかと言いますと、57は素数であり素数でない。ある意味バグ的な存在なので、発音の対象外なんです。
詳しくは「グロタンディーク素数」で調べてみてください。
まとめ
- word2vec辞書を用いて、概念をベクトルに変換
- 最初のノルムを計算。 とする。
- 最後の次元を消し、正規化(その時点でのノルムで、すべての成分を除す)
- 正規化したベクトルのすべての成分に をかける
- 3,4を、次元数10になるまで繰り返す
- 元ベクトルの準備完了
- 2個ずつに分ける
- これは2軸ずつの分割なので、それぞれの成分のベクトルを平面上に投影できる
- それぞれのベクトルとx軸がなす角度を求める(atan2)
- 点を描き、書き進める方向をx軸とする
- それに、求めた5つの角度に沿う半直線を、点を始点に描く(大体合ってればいい)
- 文字完成
- 絶対値ノルム(総和ノルムとも)を求める
- 整数桁に変換(小数点外す)
- 2桁ごとに分割する
- それぞれを発音に置換
- 発音完成
どこか間違えてたらすいません。数学が専門なわけではなくて...
コードを試してエラーが出たら、私に聞いてください。多分大体解決します。
では、みなさんもよき数学ライフを送ってください。




新しい順のコメント(0)