みなさん、こんにちは。skytomoと申します。
この記事は「語学・言語学・言語創作 Advent Calendar 2025」の2日目の記事です。
この記事では、以下のことについて述べます。
- 辞書形式の現状と問題点
- 最強の辞書アプリを作りたかった話
- 最強の辞書形式を考えてみる
はじめに
人工言語には辞書がつきものです。
日本の人工言語コミュニティで主流な辞書形式は以下の2つだと思っています。
- Excel(TSVとかCSV形式)
- OTM-JSON形式
簡単な単語帳を作るのであれば、Excelで十分ですが、ある程度言語が成熟してくると、ちゃんとした辞書っぽいものを作りたくなると思います。その際に、OTM-JSON形式がよく使われます。OTM-JSON形式に対応した辞書アプリもあります。
すみません、私の知らないところで実はもっと有名なものがあるのかもしれませんが、私の知る限りでは、OTM-JSON形式が今も一番メジャーな辞書形式だと思っています。(もし何か他に話題になっている辞書形式があるのであれば教えて下さい)
OTM-JSON形式の問題点
OTM-JSONはわかりやすくて、長い間使われている辞書形式ですが、軽微なことでいくつか困ることがあります。
正式な表現方法が足りないときがある
OTM-JSON形式にはversion 1とversion 2があります。ここではOTM-JSON version 2を前提に話をします。
version 2は1とほとんど同じですが、トップレベルに余分なキーをもつことが許されるのに加え、内のあらゆるオブジェクトに関しても余分なキーをもつことが許されるようになりました。要するに、OTM-JSONは自由に拡張可能になったわけです。
例えば、OTM-JSONでは例文を正式に表す方法がありませんが、ZpDIC Onlineでは、辞書をJSONファイルに変換するときに、OTM-JSONを拡張して例文を表現しています。
https://zpdic.ziphil.com/document/other/json-spec
{
"version": 2,
"words": [/* ... */],
"examples": [
{
"id": 7,
"sentence": "mi jan Sewitomo.",
"translation": "私はskytomoです。",
"words": [
{
"id": 1
},
{
"id": 2
}
]
}
]
}
他にも、ZpDIC OnlineのOTM-JSON拡張では、ZpDIC Online特有の情報も保存しています。
{
/* ... */
"zpdicOnline": {
"explanation": "辞書の説明",
"punctuations": [
",",
"、",
"。"
],
"ignoredPattern": "[\\((].*?[\\))]",
"pronunciationTitle": "Pronunciation",
"enableMarkdown": true
}
}
また、おかゆさんのOTM-JSON拡張では、辞書の対象言語を保存しています。
https://github.com/cogas/jbovlaste_otmize/blob/master/vlaste_builder.py#L60
{
/* ... */
"meta": {
"lang": {
"to": "ja",
"from": "jbo"
},
"generated_date": "2016-12-13"
}
}
以上より、OTM-JSON形式は正式に表現できない情報を拡張で補うことができる一方で、拡張の方法が人によってバラバラになりがちである、という問題があります。
辞書の対象言語や例文のような、辞書にとって重要な情報は、正式な表現方法としてほしくないですか?
また、OTM-JSON形式では、画像や音声ファイルを扱う方法もありません。例えば、以下のように画像や音声ファイルを扱う拡張が考えられます。
{
/* ... */
"media": [
{
"id": 1,
"type": "image",
"url": "https://example.com/image1.png",
"description": "An example image"
},
{
"id": 2,
"type": "audio",
"url": "https://example.com/audio1.mp3",
"description": "An example audio"
}
]
}
この方法はURLを使って外部ファイルを参照する方法ですが、外部ファイルが削除されたり移動されたりするとリンク切れになってしまいます。また、OTM-JSONの利点である「1つのJSONファイルで辞書全体を管理できる」という点も失われてしまいます。
もしくは、ファイルに直接埋め込む方法もあります。
{
/* ... */
"media": [
{
"id": 1,
"type": "image",
"data": "data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAA...",
"description": "An example image"
},
{
"id": 2,
"type": "audio",
"data": "data:audio/mp3;base64,//uQZAAAAAAAAAAAAAAAAAAAA...",
"description": "An example audio"
}
]
}
画像や音声ファイルはバイナリファイルですが、Base64(バイナリファイルをテキストに変換する方法)を使えばJSONファイルに埋め込むことができます。
この方法であれば、リンク切れの心配はありません。
大きいファイルは編集が大変
OTM-JSON形式は1つのJSONファイルで辞書全体を管理します。これは配布やバックアップが簡単になるという利点がありますが、ファイルが大きくなると編集が大変になる、という欠点もあります。
私は約20 dBTOK(=12000語)の単語が収録されているOTM-JSONを扱ったことがありますが、ここまで来るとかなり限界を感じます。
先程の画像や音声ファイルをBase64で埋め込む方法を使うと、ファイルサイズが非常に大きくなり、編集がさらに大変になります。
OTM-JSONの「テキストエディタで編集できる」という利点も失われてしまいます。
最強の辞書アプリを作りたかった話
そこで、私は数年前から最強の辞書アプリを作りたいと思っていました。最強の辞書形式を考えるのは難しいので、一旦それは置いといて、どんな辞書形式が来てもアプリに対応できるような最強な辞書アプリを作ろうと決意しました。
そうすれば、後から辞書形式の問題点を解決した新しい辞書形式がいくら出てきても、アプリ側で対応できると思ったからです。
しかし、この試みは非常に難航しました。当たり前ではあるのですが、辞書形式ごとにデータの扱い方が異なるため、抽象的な部分が多く、いくつもの種類の拡張機能を作る必要がある、複雑な設計になってしまったのです。
最終的に、私はこの試みを半ば断念しました。
仮に作ったとしても、今度は辞書形式の開発者がいくつもの拡張機能を作る必要があるため、実用化は難しいと思いました。
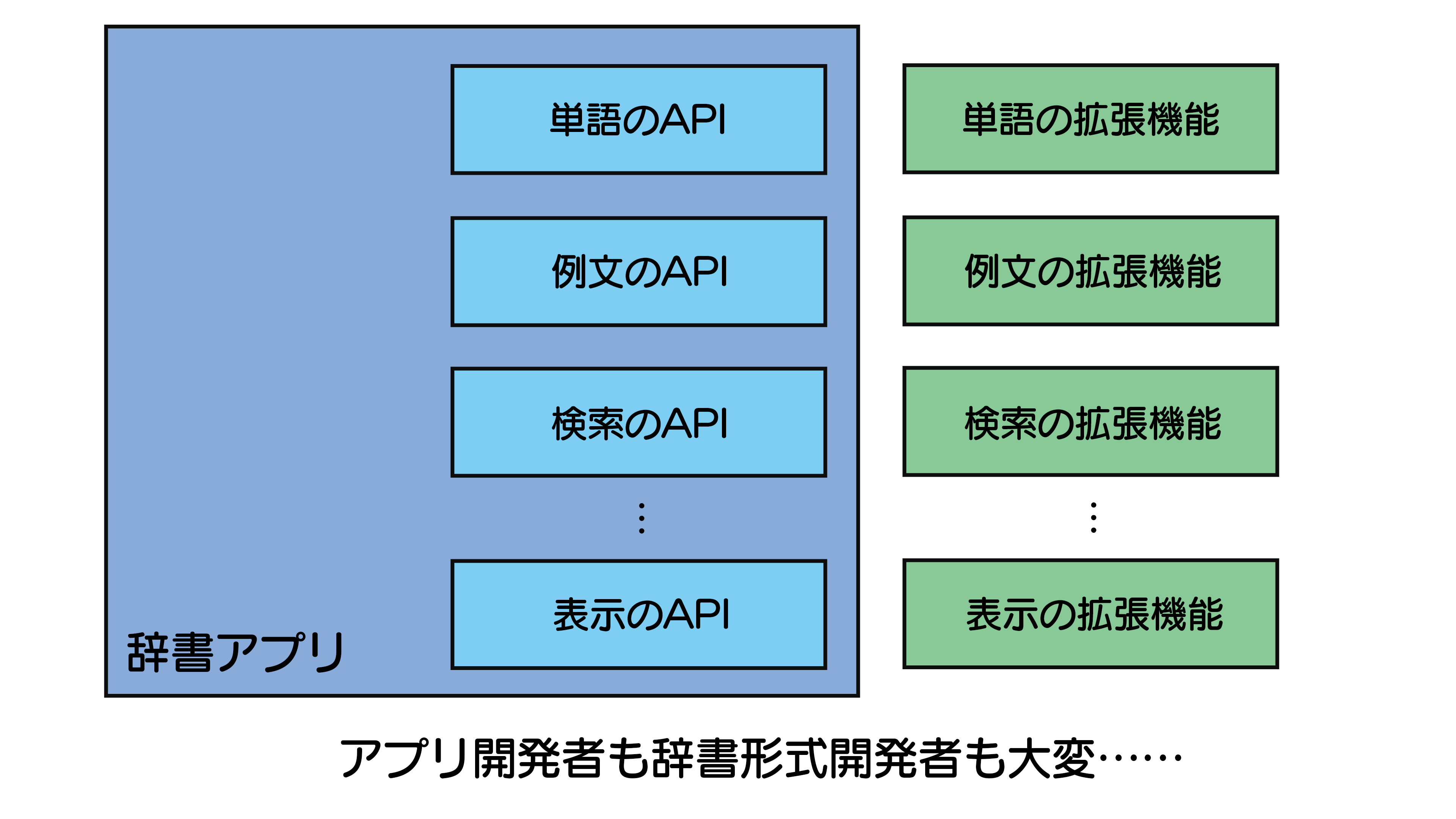
そこで、最強の辞書形式を考えてみることにしました。
最強の辞書形式を一つつくれば、それをサポートした辞書アプリも一つで済みます。
ここでは機能をてんこ盛りにした辞書形式を仮にTenkomori形式と呼ぶことにします。
必要があればTenkomori形式をOTM-JSON形式など他の辞書形式に変換することもできます。
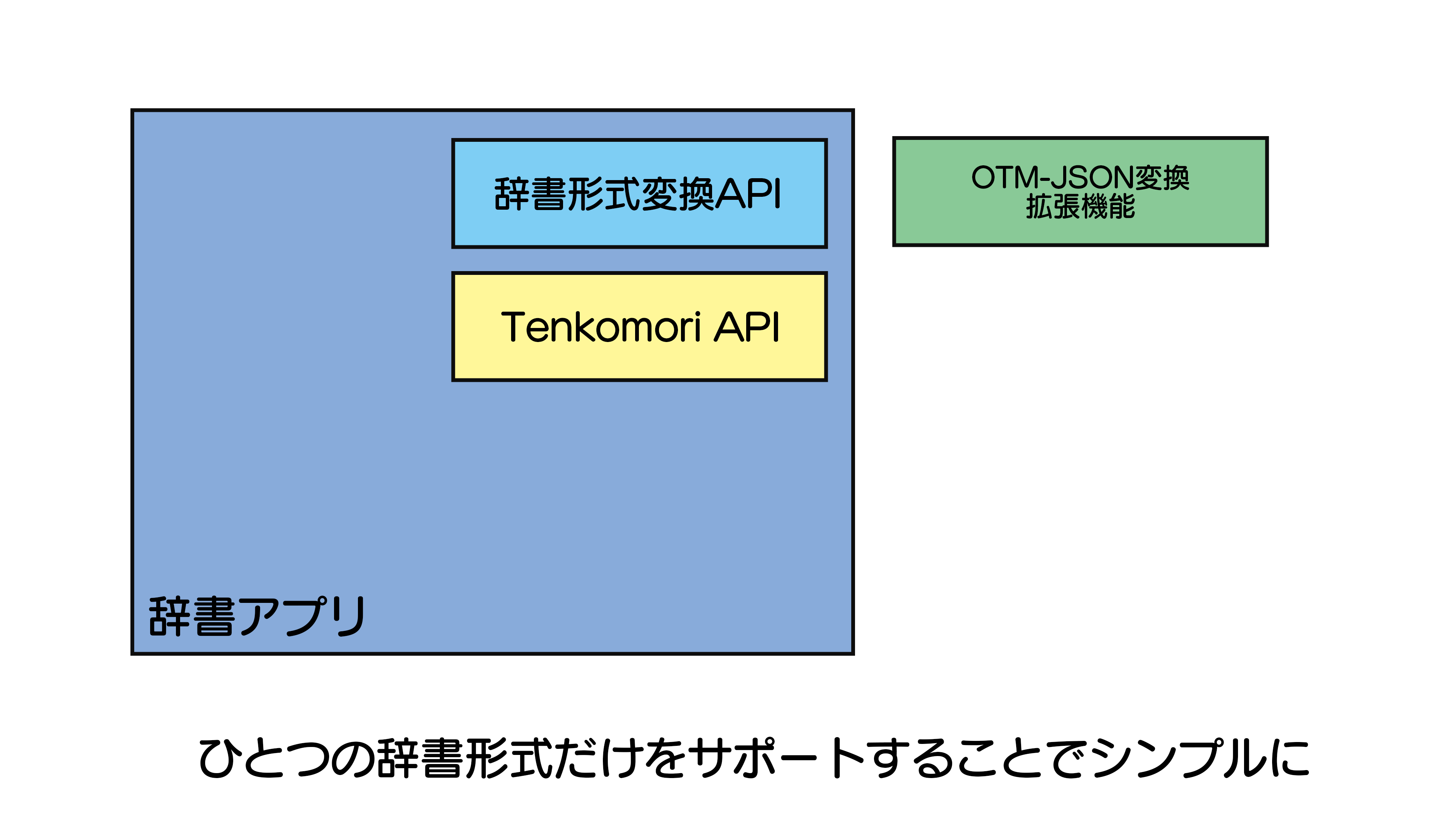
これで別の辞書形式開発者もインポート・エクスポート拡張機能を一つ作るだけで済みます。
非常にシンプルな構成になります。
最強の辞書形式を考えてみる
やっとここで本題です。
じゃあ、最強の辞書形式って具体的にどんな形式であってほしいでしょうか?
以下にまとめてみました。
- 表現方法が豊富な形式
- 例文、画像、音声ファイルなども拡張せずに表現できる
- 別の辞書形式からの変換が容易
- 単語数やメディアファイルが多くても扱いやすい
- 人間が直接編集しやすい形式
- 辞書アプリが扱いやすい形式
- 機械可読性も高い形式
- 配布時には1つのファイルにまとめられる
- ファイルサイズは小さいほうが良い
以上の要件を満たす辞書形式として、私は以下のような辞書形式を考えました。
- 開発時と配布時で形式を分ける
- 開発時
- 基本的に辞書データはTOML形式かXML形式を採用
- 複数ファイルで管理
- メディアファイルは別ファイルで管理
- 単語データはそれぞれ別ファイルで管理
- 配布時
- sqlite形式のデータベースファイルにまとめる
もうちょっと具体的に見てみましょう。
開発時のファイル構成例
辞書プロジェクトフォルダ/
├── assets/
├── corpora/
│ └── examples.xml
├── words/
│ ├── mi.toml
│ └── jan.toml
└── settings.toml
開発時のファイル構成は上記のようになります。
(スキーマとかはまだ確定していません)
- assets/:画像や音声ファイルなどのメディアファイルを格納するフォルダ
- corpora/:例文などのコーパスデータを格納するフォルダ
- words/:単語データを格納するフォルダ
- settings.toml:辞書全体の設定ファイル
このような構成になっています。
単語は1ファイル1単語で管理することで、複数人での編集がしやすくなります。
# words/mi.toml
[lemma]
form = "mi"
[[pronunciations]]
pronunciation = "mi"
[[equivalent_groups]]
pos = "pronoun"
[[equivalents]]
language = "ja"
equivalent = "私"
[[equivalents]]
language = "en"
equivalents = ["i", "me"]
他の単語から参照したいときはファイルパスをidとして使うことができます。
# words/sina.toml
[lemma]
form = "sina"
# ……(中略)……
[[related_words]]
id = "mi" # words/mi.toml を参照する
こうすることによって、IDをわざわざファイル内に書かなくても済みますし、うっかりIDが重複することも防げます。
しかし、ひとつのファイルに複数のデータを入れたいこともあります。
例えば、例文データはひとつひとつ分けるのは面倒です。
そういう場合はXML形式を使って複数の例文をひとつのファイルで管理することもできます。
<?xml version="1.0" encoding="UTF-8"?>
<corpus>
<example xml:id="ex-001">
<sentence>mi jan Sewitomo.</sentence>
<translation xml:lang="ja">私はskytomoです。</translation>
<translation xml:lang="en">I am skytomo.</translation>
<words>
<word id="mi"/>
<word id="jan"/>
</words>
</example>
<example xml:id="ex-002">
<sentence>mi jan sin.</sentence>
<translation xml:lang="ja">私は新人です。</translation>
<translation xml:lang="en">I am a newcomer.</translation>
<words>
<word id="mi"/>
<word id="jan"/>
<word id="sin"/>
</words>
</example>
</corpus>
上記のは例で、具体的なXMLスキーマについてはまだ検討中です。
配布時のデータベース構成例
配布時にはsqlite形式のデータベースファイルにまとめます。
こうすることで、配布が簡単になり、かつファイルサイズも小さく抑えられます。
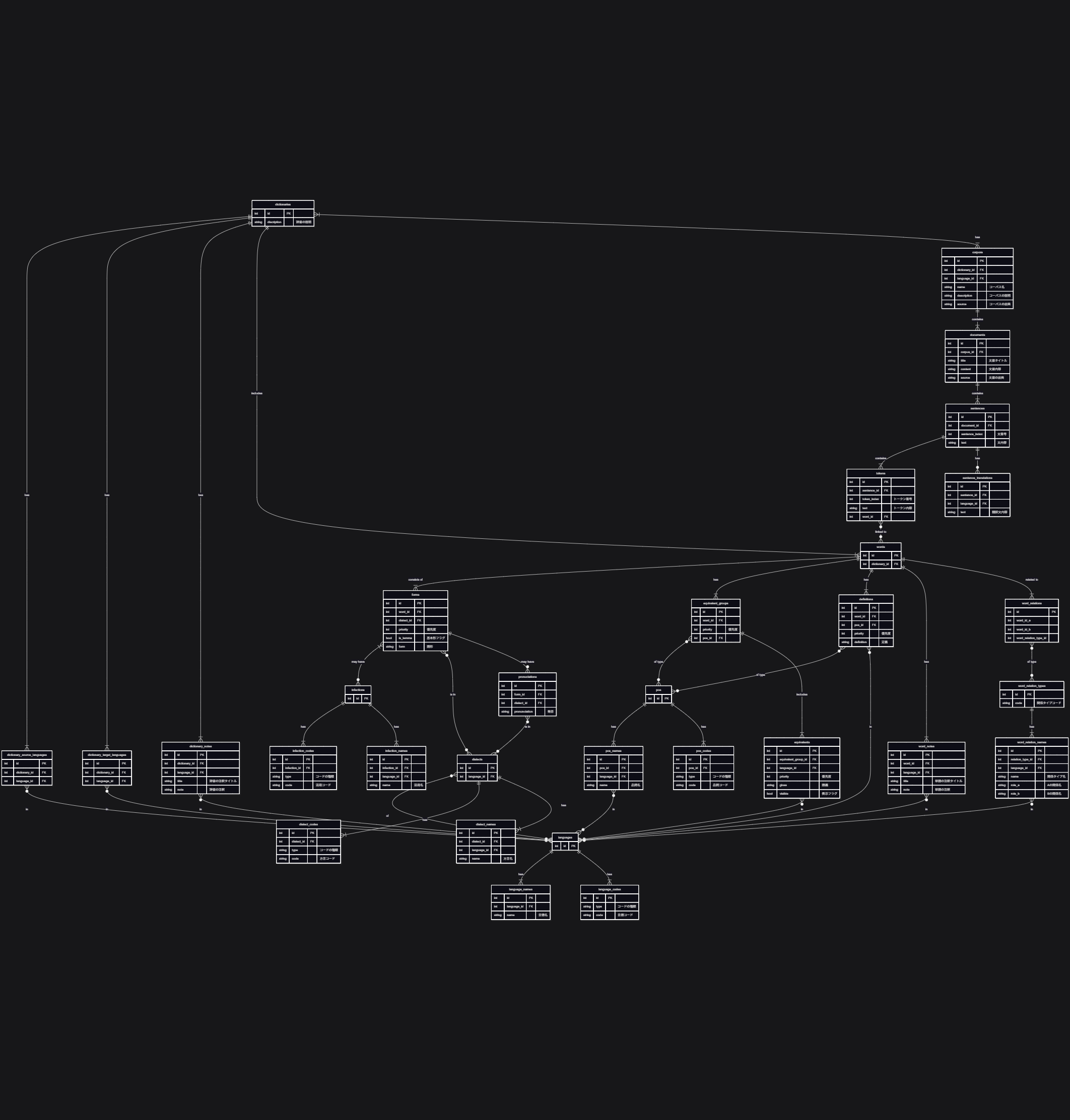
スキーマはまだ作成中ですが、ちらっとお見せするとこんな感じです。
おわりに
以上、最強の辞書形式について考えてみました。
次のステップとしてこのファイル形式に対応したプログラムを作成したいと思います。
こういう表現がほしい! という方や、改善案などがありましたら、ぜひ教えてください。
最後までお読みいただき、ありがとうございました。
それでは、少し早いですが、よいクリスマスを!




人気順のコメント(0)